Quick Start#
If you have not installed MARLlib yet, please refer to Installation before running.
Configuration Overview#
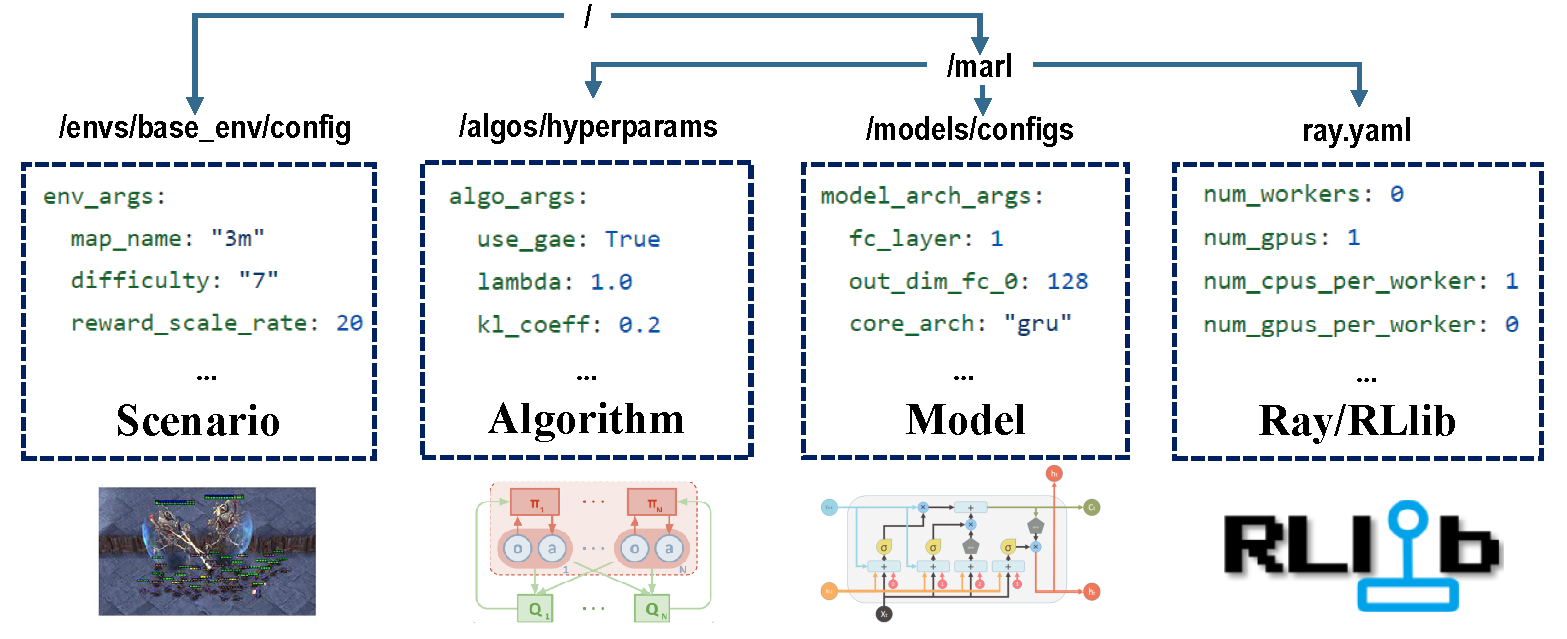
Prepare all the configuration files to start your MARL journey#
To start your MARL journey with MARLlib, you need to prepare all the configuration files to customize the whole learning pipeline. There are four configuration files that you need to ensure correctness for your training demand:
scenario: specify your environment/task settings
algorithm: finetune your algorithm hyperparameters
model: customize the model architecture
ray/rllib: changing the basic training settings
Scenario Configuration#
MARLlib provides ten environments for you to conduct your experiment. You can follow the instruction in the Environments section to install them and change the corresponding configuration to customize the chosen task.
Algorithm Hyper-parameter#
After setting up the environment, you need to visit the MARL algorithms’ hyper-parameter directory. Each algorithm has different hyper-parameters that you can finetune. Most of the algorithms are sensitive to the environment settings. Therefore, you need to give a set of hyper-parameters that fit the current MARL task.
We provide a commonly used hyper-parameters directory, a test-only hyper-parameters directory, and a finetuned hyper-parameters sets for the three most used MARL environments, including SMAC , MPE, and MAMuJoCo
Model Architecture#
Observation space varies with different environments. MARLlib automatically constructs the agent model to fit the diverse input shape, including: observation, global state, action mask, and additional information (e.g., minimap)
However, you can still customize your model in model’s config. The supported architecture change includes:
Recurrent Neural Network: GRU, LSTM
Q/Critic Value Mixer: VDN, QMIX
Ray/RLlib Running Options#
Ray/RLlib provides a flexible multi-processing scheduling mechanism for MARLlib. You can modify the file of ray configuration to adjust sampling speed (worker number, CPU number), training speed (GPU acceleration), running mode (locally or distributed), parameter sharing strategy (all, group, individual), and stop condition (iteration, reward, timestep).
How to Customize#
To modify the configuration settings in MARLlib, it is important to first understand the underlying configuration system.
Level of the configuration#
There are three levels of configuration, listed here in order of priority from low to high:
File-based configuration, which includes all the default
*.yamlfiles.API-based customized configuration, which allows users to specify their own preferences, such as
{"core_arch": "mlp", "encode_layer": "128-256"}.Command line arguments, such as
python xxx.py --ray_args.local_mode --env_args.difficulty=6 --algo_args.num_sgd_iter=6.
If a parameter is set at multiple levels, the higher level configuration will take precedence over the lower level configuration.
Compatibility across different levels#
It is important to ensure that hyperparameter choices are compatible across different levels.
For example, the Multiple Particle Environments (MPE) support both discrete and continuous actions.
To enable continuous action space settings, one can simply change the continuous_actions parameter in the mpe.yaml to True.
It is important to pay attention to the corresponding setting when using the API-based approach or command line arguments, such as marl.make_env(xxxx, continuous_actions=True), where the argument name must match the one in mpe.yaml exactly.
Training#
from marllib import marl
# prepare env
env = marl.make_env(environment_name="mpe", map_name="simple_spread")
# initialize algorithm with appointed hyper-parameters
mappo = marl.algos.mappo(hyperparam_source="mpe")
# build agent model based on env + algorithms + user preference
model = marl.build_model(env, mappo, {"core_arch": "mlp", "encode_layer": "128-256"})
# start training
mappo.fit(env, model, stop={"timesteps_total": 1000000}, checkpoint_freq=100, share_policy="group")
prepare the environment#
task mode |
api example |
|---|---|
cooperative |
|
collaborative |
|
competitive |
|
mixed |
|
Most of the popular environments in MARL research are supported by MARLlib:
Env Name |
Learning Mode |
Observability |
Action Space |
Observations |
|---|---|---|---|---|
cooperative + collaborative |
Both |
Discrete |
1D |
|
cooperative |
Partial |
Discrete |
1D |
|
cooperative + collaborative + mixed |
Both |
Both |
1D |
|
cooperative |
Partial |
Discrete |
1D |
|
collaborative |
Partial |
Continuous |
1D |
|
collaborative + mixed |
Partial |
Discrete |
2D |
|
collaborative + competitive + mixed |
Both |
Discrete |
2D |
|
cooperative |
Partial |
Continuous |
1D |
|
collaborative + mixed |
Full |
Discrete |
2D |
|
cooperative |
Partial |
Discrete |
1D |
Each environment has a readme file, standing as the instruction for this task, including env settings, installation, and important notes.
initialize the algorithm#
running target |
api example |
|---|---|
train & finetune |
|
develop & debug |
|
3rd party env |
|
Here is a chart describing the characteristics of each algorithm:
algorithm |
support task mode |
discrete action |
continuous action |
policy type |
|---|---|---|---|---|
all four |
|
off-policy |
||
IPG |
all four |
|
|
on-policy |
all four |
|
|
on-policy |
|
all four |
|
off-policy |
||
all four |
|
|
on-policy |
|
all four |
|
|
on-policy |
|
COMA: MAA2C with Counterfactual Multi-Agent Policy Gradients |
all four |
|
on-policy |
|
all four |
|
off-policy |
||
all four |
|
|
on-policy |
|
all four |
|
|
on-policy |
|
all four |
|
|
on-policy |
|
cooperative |
|
|
on-policy |
|
cooperative |
|
|
on-policy |
|
cooperative |
|
off-policy |
||
cooperative |
|
off-policy |
||
cooperative |
|
off-policy |
||
cooperative |
|
|
on-policy |
|
cooperative |
|
|
on-policy |
*all four: cooperative collaborative competitive mixed
construct the agent model#
model arch |
api example |
|---|---|
MLP |
|
GRU |
|
LSTM |
|
encoder arch |
|
kick off the training algo.fit#
setting |
api example |
|---|---|
train |
|
debug |
|
stop condition |
|
policy sharing |
|
save model |
|
GPU accelerate |
|
CPU accelerate |
|
policy inference algo.render
setting |
api example |
|---|---|
render |
|
By default, all the models will be saved at /home/username/ray_results/experiment_name/checkpoint_xxxx
Logging & Saving#
MARLlib uses the default logger provided by Ray in ray.tune.CLIReporter. You can change the saved log location here.