Environments#
Environment list of MARLlib, including installation and description.
Note: make sure you have read and completed the Installation part.
SMAC#
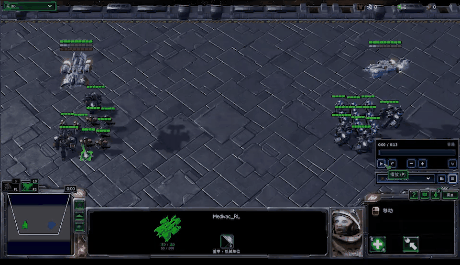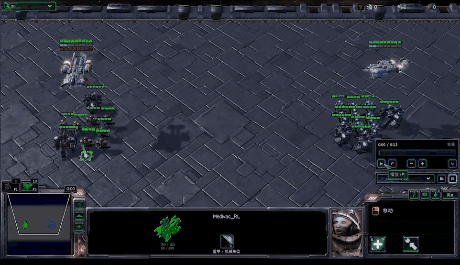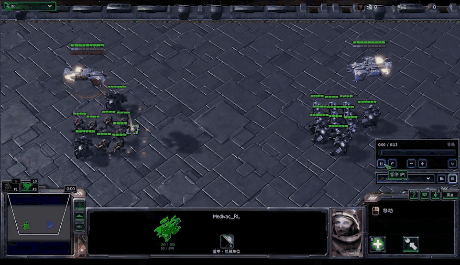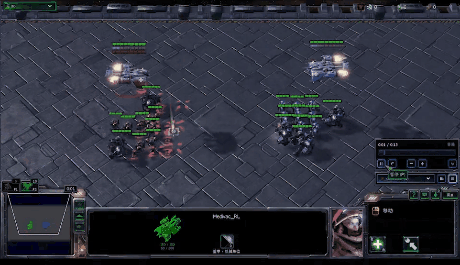
StarCraft Multi-Agent Challenge (SMAC) is a multi-agent environment for collaborative multi-agent reinforcement learning (MARL) research based on Blizzard’s StarCraft II RTS game. It focuses on decentralized micromanagement scenarios, where an individual RL agent controls each game unit.
Official Link: oxwhirl/smac
|
Cooperative |
|
Cooperative + Collaborative |
|
Partial |
|
Discrete |
|
1D |
|
Yes |
|
Yes |
|
1D |
|
Dense / Sparse |
|
Simultaneous |
Installation#
bash install_sc2.sh # https://github.com/oxwhirl/pymarl/blob/master/install_sc2.sh
pip3 install numpy scipy pyyaml matplotlib
pip3 install imageio
pip3 install tensorboard-logger
pip3 install pygame
pip3 install jsonpickle==0.9.6
pip3 install setuptools
pip3 install sacred
git clone https://github.com/oxwhirl/smac.git
cd smac
pip install -e .
Note: the location of the StarcraftII game directory should be pre-defined, or you can just follow the error log (when the process can not found the game’s location) and put it in the right place.
API usage#
from marllib import marl
env = marl.make_env(environment_name="smac", map_name="3m", difficulty="7", reward_scale_rate=20)
MPE#

Multi-particle Environments (MPE) are a set of communication-oriented environments where particle agents can (sometimes) move, communicate, see each other, push each other around, and interact with fixed landmarks.
Official Link: openai/multiagent-particle-envs
Our version: Farama-Foundation/PettingZoo
|
Collaborative + Competitive |
|
Cooperative + Collaborative + Competitive + Mixed |
|
Full |
|
Discrete + Continuous |
|
1D |
|
No |
|
No |
|
/ |
|
Dense |
|
Simultaneous / Asynchronous |
PettingZoo#

PettingZoo has undergone significant updates, and we have made the decision to seamlessly integrate its latest version with Gymnasium, using Multi-Agent Particle Environment (MPE) as a prime example. This integration serves as a blueprint for incorporating any task from the most recent PettingZoo library into MARLlib.
For detailed information and access to the official PettingZoo repository, please visit the following link: Farama-Foundation/PettingZoo.
In addition, there are some optional installation steps you may want to consider for your specific use case.
pip install pettingzoo==1.23.1
pip install supersuit==3.9.0
pip install pygame==2.3.0
API usage#
from marllib import marl
env = marl.make_env(environment_name="gymnasium_mpe", map_name="simple_spread")
MAMuJoCo#

Multi-Agent Mujoco (MAMuJoCo) is an environment for continuous cooperative multi-agent robotic control. Based on the popular single-agent robotic MuJoCo control suite provides a wide variety of novel scenarios in which multiple agents within a single robot have to solve a task cooperatively.
Official Link: schroederdewitt/multiagent_mujoco
|
Cooperative |
|
Cooperative + Collaborative |
|
Partial |
|
Continuous |
|
1D |
|
No |
|
Yes |
|
1D |
|
Dense |
|
Simultaneous |
Installation#
mkdir /home/YourUserName/.mujoco
cd /home/YourUserName/.mujoco
wget https://roboti.us/download/mujoco200_linux.zip
unzip mujoco200_linux.zip
export LD_LIBRARY_PATH=/home/YourUserName/.mujoco/mujoco200/bin;
pip install mujoco-py==2.0.2.8
git clone https://github.com/schroederdewitt/multiagent_mujoco
cd multiagent_mujoco
mv multiagent_mujoco /home/YourPathTo/MARLlib/multiagent_mujoco
# optional
sudo apt-get install libosmesa6-dev # If you meet GCC error with exit status 1
pip install patchelf-wrapper
Note: To access the MuJoCo API, you may get a mjkey (free now) and put it under /home/YourUserName/.mujoco.
API usage#
from marllib import marl
env = marl.make_env(environment_name="mamujoco", map_name="2AgentHalfCheetah")
Gymnasium MAMuJoCo#
We have recently updated the MAMuJoCo to its latest version, which is now maintained by Gymnasium Robotics. You can find the updated version at the following link: https://robotics.farama.org/envs/MaMuJoCo/
The task characteristics remain the same as described in the MAMuJoCo.
Installing the updated version is a straightforward process if you already get MuJoCo at hand.
pip install gymnasium-robotics==1.2.2
API usage#
from marllib import marl
env = marl.make_env(environment_name="gymnasium_mamujoco", map_name="2AgentHalfCheetah")
Google Research Football#
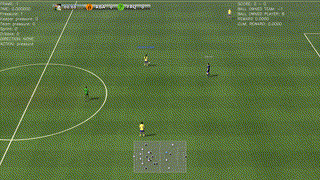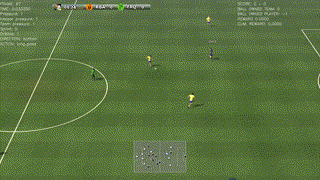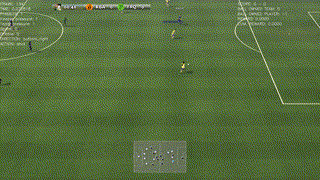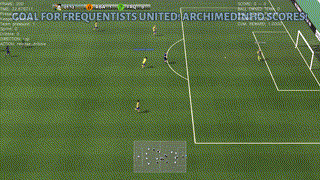
Google Research Football (GRF) is a reinforcement learning environment where agents are trained to play football in an advanced, physics-based 3D simulator. It also provides support for multiplayer and multi-agent experiments.
Official Link: google-research/football
|
Collaborative + Competitive |
|
Cooperative + Collaborative |
|
Full |
|
Discrete |
|
2D |
|
No |
|
No |
|
/ |
|
Sparse |
|
Simultaneous |
Installation#
Google Research Football is somehow a bit tricky for installation. We wish you good luck.
sudo apt-get install git cmake build-essential libgl1-mesa-dev libsdl2-dev libsdl2-image-dev libsdl2-ttf-dev libsdl2-gfx-dev libboost-all-dev libdirectfb-dev libst-dev mesa-utils xvfb x11vnc python3-pip
python3 -m pip install --upgrade pip setuptools psutil wheel
We provide solutions (may work) for potential bugs
API usage#
from marllib import marl
env = marl.make_env(environment_name="football", map_name="academy_pass_and_shoot_with_keeper")
SISL#

The SISL environments are a set of three cooperative multi-agent benchmark environments, created at SISL (Stanford Intelligent Systems Laboratory)) and released as part of “Cooperative multi-agent control using deep reinforcement learning.”
Official Link: sisl/MADRL
Our version: Farama-Foundation/PettingZoo
|
Cooperative |
|
Cooperative + Collaborative |
|
Full |
|
Discrete + Continuous |
|
1D |
|
No |
|
No |
|
/ |
|
Dense |
|
Simultaneous / Asynchronous |
Installation#
We use the pettingzoo version of SISL
pip install pettingzoo[sisl]
API usage#
from marllib import marl
# cooperative mode
env = marl.make_env(environment_name="sisl", map_name="multiwalker", force_coop=True)
# Collaborative mode
env = marl.make_env(environment_name="sisl", map_name="multiwalker")
LBF#
Level-based Foraging (LBF) is a mixed cooperative-competitive game that focuses on coordinating the agents involved. Agents navigate a grid world and collect food by cooperating with other agents if needed.
Official Link: semitable/lb-foraging
|
Cooperative + Collaborative |
|
Cooperative + Collaborative |
|
Partial |
|
Discrete |
|
1D |
|
No |
|
No |
|
/ |
|
Dense |
|
Simultaneous |
Installation#
pip install lbforaging==1.0.15
API usage#
from marllib import marl
# use default setting marllib/envs/base_env/config/lbf.yaml
env = marl.make_env(environment_name="lbf", map_name="default_map")
# customize yours
env = marl.make_env(environment_name="lbf", map_name="customized_map", force_coop=True, players=4, field_size_x=8)
RWARE#
Robot Warehouse (RWARE) simulates a warehouse with robots moving and delivering requested goods. Real-world applications inspire the simulator, in which robots pick up shelves and deliver them to a workstation.
Official Link: semitable/robotic-warehouse
|
Cooperative |
|
Cooperative + Collaborative |
|
Partial |
|
Discrete |
|
1D |
|
No |
|
No |
|
/ |
|
Sparse |
|
Simultaneous |
Installation#
pip install rware==1.0.1
API usage#
from marllib import marl
# use default setting marllib/envs/base_env/config/rware.yaml
env = marl.make_env(environment_name="rware", map_name="default_map")
# customize yours
env = marl.make_env(environment_name="rware", map_name="customized_map", players=4, map_size="tiny")
MAgent#
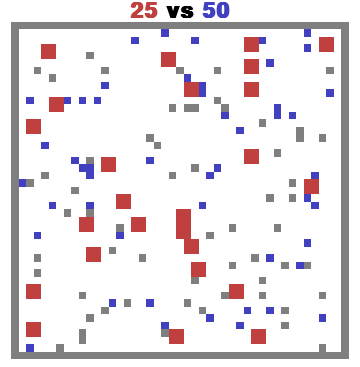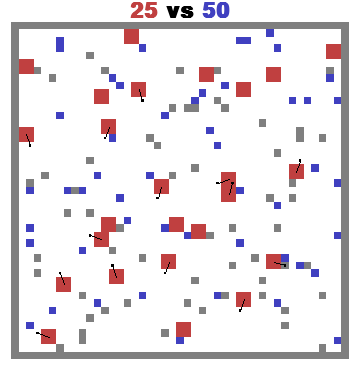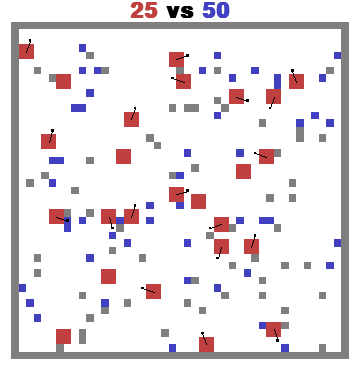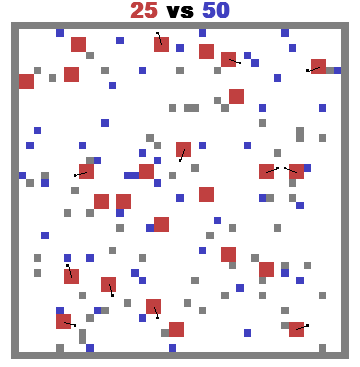
MAgent is a set of environments where large numbers of pixel agents in a grid world interact in battles or other competitive scenarios.
Official Link: https://www.pettingzoo.ml/magent
Our version: Farama-Foundation/PettingZoo
|
Collaborative + Competitive |
|
Collaborative + Competitive |
|
Partial |
|
Discrete |
|
2D |
|
No |
|
MiniMap |
|
2D |
|
Dense |
|
Simultaneous / Asynchronous |
Installation#
pip install pettingzoo[magent]
API usage#
from marllib import marl
env = marl.make_env(environment_name="magent", map_name="adversarial_pursuit")
# turn off minimap; need to change global_state_flag to False
env = marl.make_env(environment_name="magent", map_name="adversarial_pursuit", minimap_mode=False)
Pommerman#

Pommerman is stylistically similar to Bomberman, the famous game from Nintendo. Pommerman’s FFA is a simple but challenging setup for engaging adversarial research where coalitions are possible, and Team asks agents to be able to work with others to accomplish a shared but competitive goal.
Official Link: MultiAgentLearning/playground
|
Collaborative + Competitive |
|
Cooperative + Collaborative + Competitive + Mixed |
|
Full |
|
Discrete |
|
2D |
|
No |
|
No |
|
/ |
|
Sparse |
|
Simultaneous |
Installation#
git clone https://github.com/MultiAgentLearning/playground
cd playground
pip install .
cd /home/YourPathTo/MARLlib/patch
python add_patch.py --pommerman
pip install gym==0.21.0
API usage#
from marllib import marl
# competitive mode
env = marl.make_env(environment_name="pommerman", map_name="PommeFFACompetition-v0")
# cooperative mode
env = marl.make_env(environment_name="pommerman", map_name="PommeTeamCompetition-v0", force_coop=True)
MetaDrive#
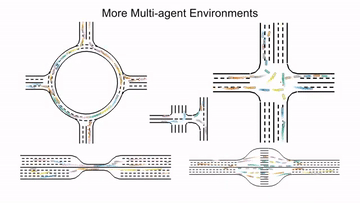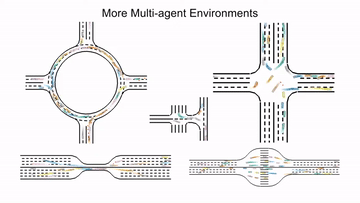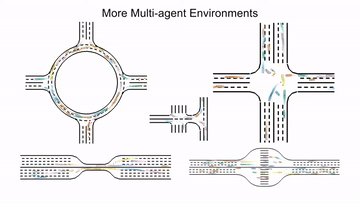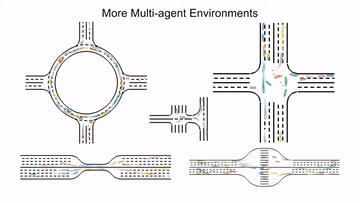
MetaDrive is a driving simulator that supports generating infinite scenes with various road maps and traffic settings to research generalizable RL. It provides accurate physics simulation and multiple sensory inputs, including Lidar, RGB images, top-down semantic maps, and first-person view images.
Official Link: decisionforce/metadrive
|
Collaborative |
|
Collaborative |
|
Partial |
|
Continuous |
|
1D |
|
No |
|
No |
|
/ |
|
Dense |
|
Simultaneous |
Installation#
pip install metadrive-simulator==0.2.3
API usage#
from marllib import marl
env = marl.make_env(environment_name="metadrive", map_name="Bottleneck")
Hanabi#
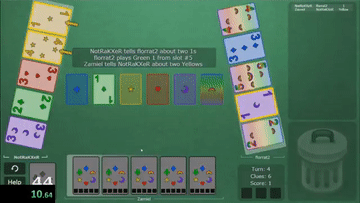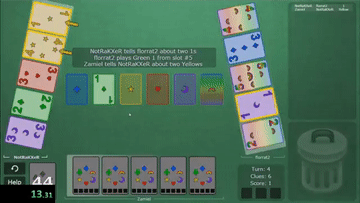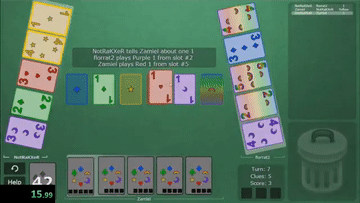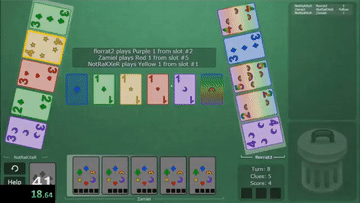
Hanabi is a cooperative card game created by French game designer Antoine Bauza. Players are aware of other players’ cards but not their own and attempt to play a series of cards in a specific order to set off a simulated fireworks show.
Official Link: deepmind/hanabi-learning-environment
|
Collaborative |
|
Collaborative |
|
Partial |
|
Discrete |
|
1D |
|
Yes |
|
Yes |
|
1D |
|
Dense |
|
Asynchronous |
Installation#
From MAPPO official site
The environment code for Hanabi is developed from the open-source environment code but has been slightly modified to fit the algorithms used here. To install, execute the following:
pip install cffi
cd /home/YourPathTo/MARLlib/patch/hanabi
mkdir build
cd build
cmake ..
make -j
API usage#
from marllib import marl
env = marl.make_env(environment_name="hanabi", map_name="Hanabi-Small", num_agents=3)
MATE#
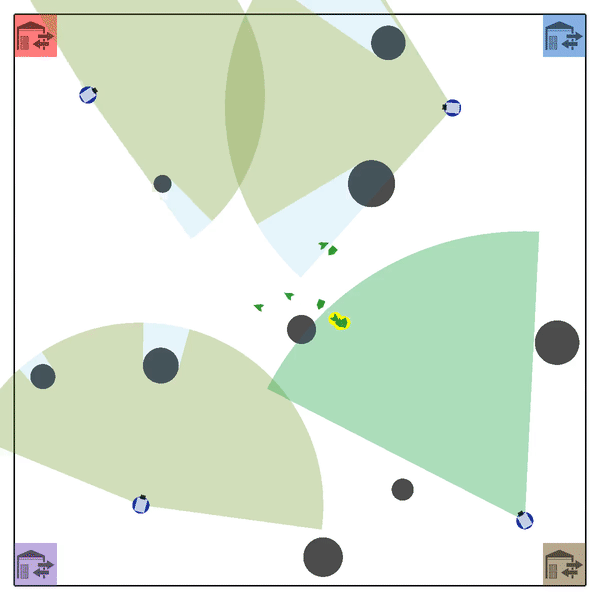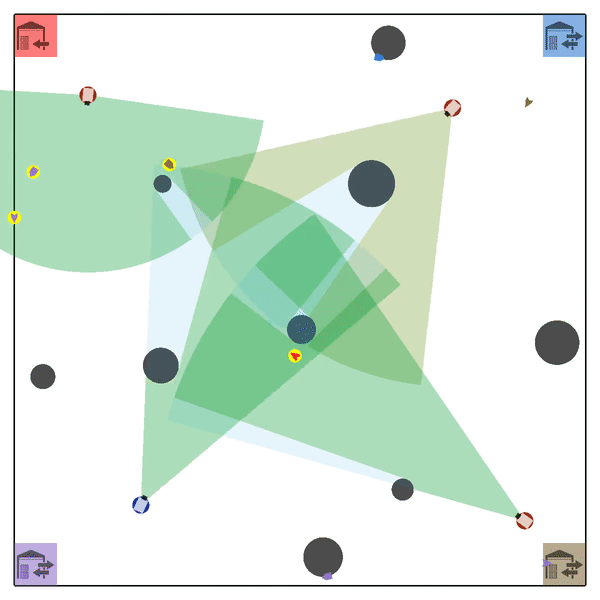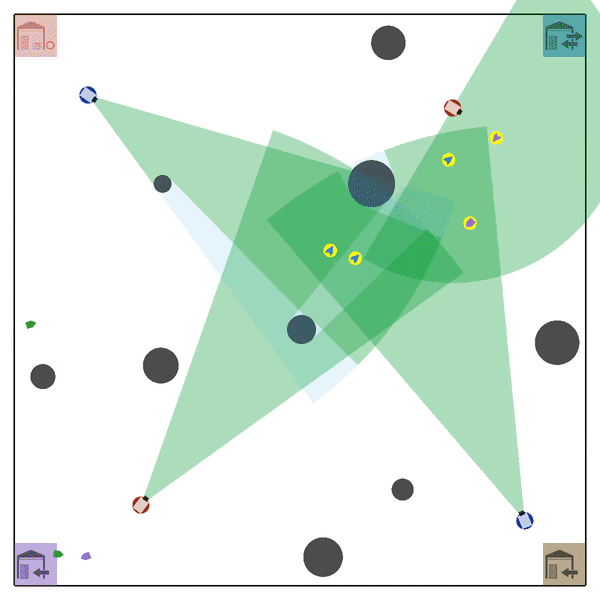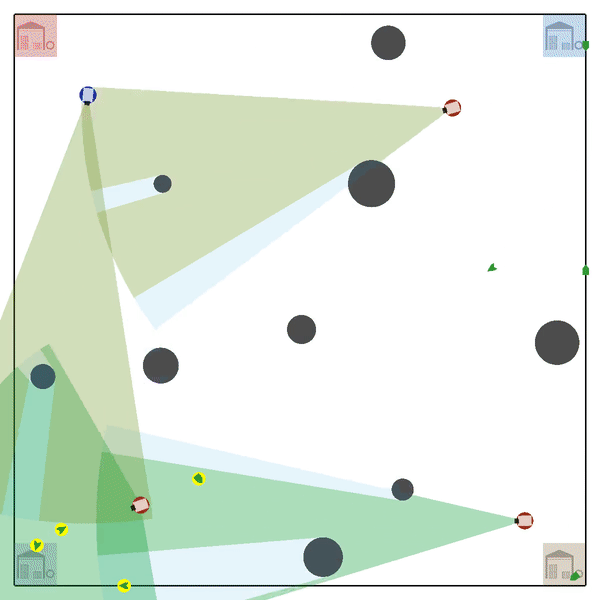
Multi-Agent Tracking Environment (MATE) is an asymmetric two-team zero-sum stochastic game with partial observations, and each team has multiple agents (multiplayer). Intra-team communications are allowed, but inter-team communications are prohibited. It is cooperative among teammates, but it is competitive among teams (opponents).
Official Link: XuehaiPan/mate
|
Cooperative + Mixed |
|
Cooperative + Mixed |
|
Partial |
|
Discrete + Continuous |
|
1D |
|
No |
|
No |
|
/ |
|
Dense |
|
Simultaneous |
Installation#
pip3 install git+https://github.com/XuehaiPan/mate.git#egg=mate
API usage#
from marllib import marl
env = marl.make_env(environment_name="mate", map_name="MATE-4v2-9-v0", coop_team="camera")
GoBigger#

GoBigger is a game engine that offers an efficient and easy-to-use platform for agar-like game development. It provides a variety of interfaces specifically designed for game AI development. The game mechanics of GoBigger are similar to those of Agar, a popular massive multiplayer online action game developed by Matheus Valadares of Brazil. The objective of GoBigger is for players to navigate one or more circular balls across a map, consuming Food Balls and smaller balls to increase their size while avoiding larger balls that can consume them. Each player starts with a single ball, but can divide it into two when it reaches a certain size, giving them control over multiple balls. Official Link: opendilab/GoBigger
|
Cooperative + Mixed |
|
Cooperative + Mixed |
|
Partial + Full |
|
Continuous |
|
1D |
|
No |
|
No |
|
/ |
|
Dense |
|
Simultaneous |
Installation#
conda install -c opendilab gobigger
API usage#
from marllib import marl
env = marl.make_env(environment_name="gobigger", map_name="st_t1p2")
Overcooked-AI#
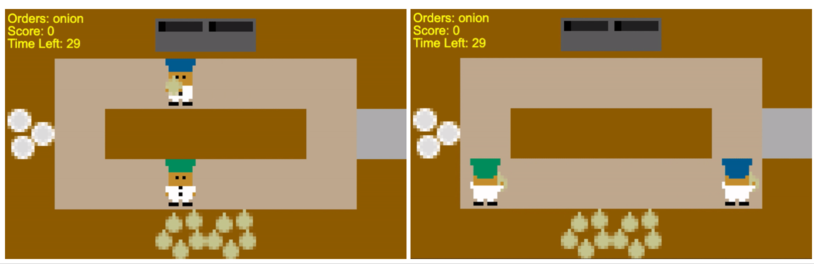
Overcooked-AI is a benchmark environment for fully cooperative human-AI task performance, based on the wildly popular video game Overcooked. Official Link: HumanCompatibleAI/overcooked_ai
|
Cooperative |
|
Cooperative |
|
Full |
|
Discrete |
|
1D |
|
No |
|
No |
|
/ |
|
Dense |
|
Simultaneous |
Installation#
git clone https://github.com/Replicable-MARL/overcooked_ai.git
cd overcooked_ai
pip install -e .
API usage#
from marllib import marl
env = marl.make_env(environment_name="overcooked", map_name="asymmetric_advantages")
Power Distribution Networks#
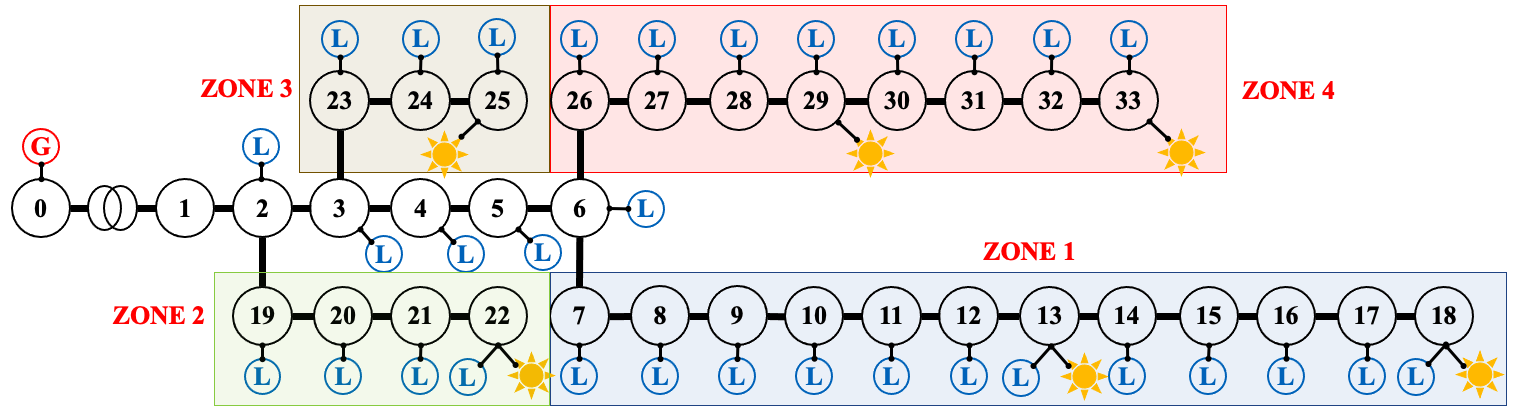
MAPDN is an environment of distributed/decentralised active voltage control on power distribution networks and a batch of state-of-the-art multi-agent actor-critic algorithms that can be used for training. Official Link: Future-Power-Networks/MAPDN
|
Cooperative |
|
Cooperative |
|
Partial |
|
Continuous |
|
1D |
|
No |
|
Yes |
|
1D |
|
Dense |
|
Simultaneous |
Installation#
Please follow this data link to download data and unzip them to $Your_Project_Path/marllib/patch/dpn or anywhere you like (need to adjust the corresponding file location to load the data).
pip install numba==0.56.4
pip install llvmlite==0.39.1
pip install pandapower==2.7.0
pip install pandas==1.1.3
API usage#
from marllib import marl
env = marl.make_env(environment_name="voltage", map_name="case33_3min_final")
Air Combat#
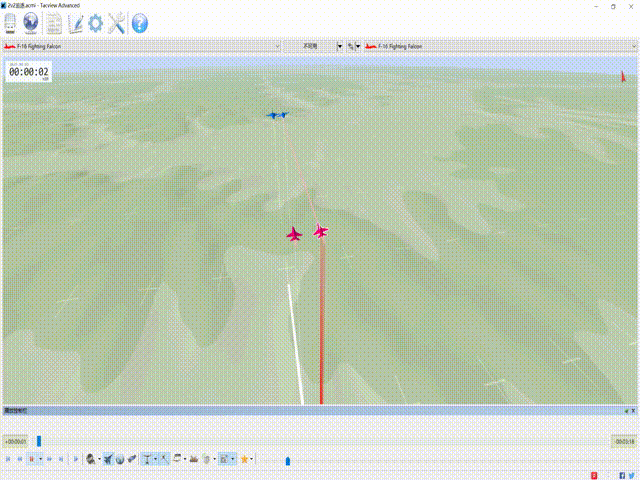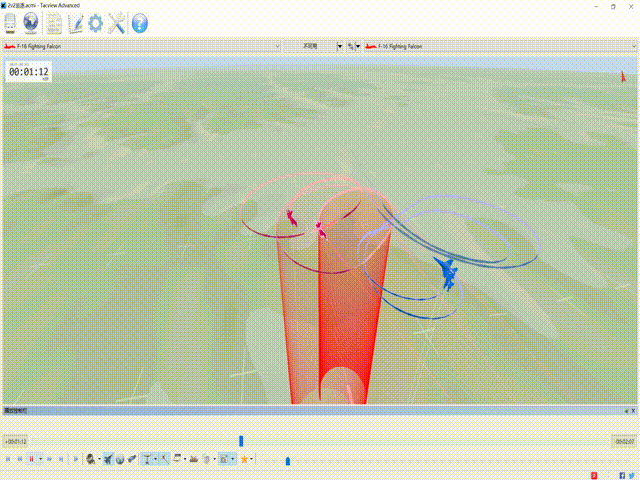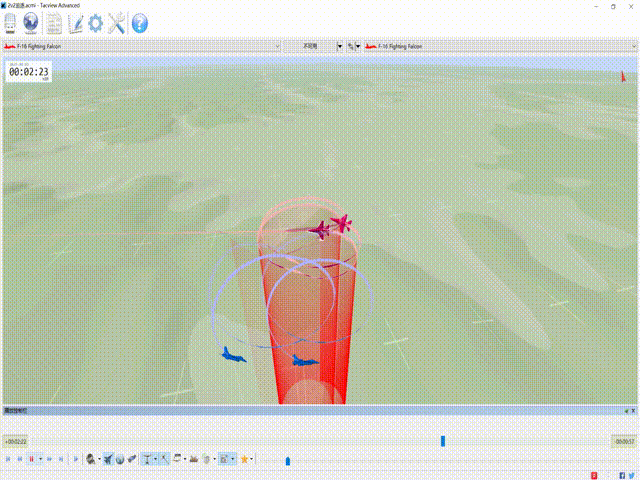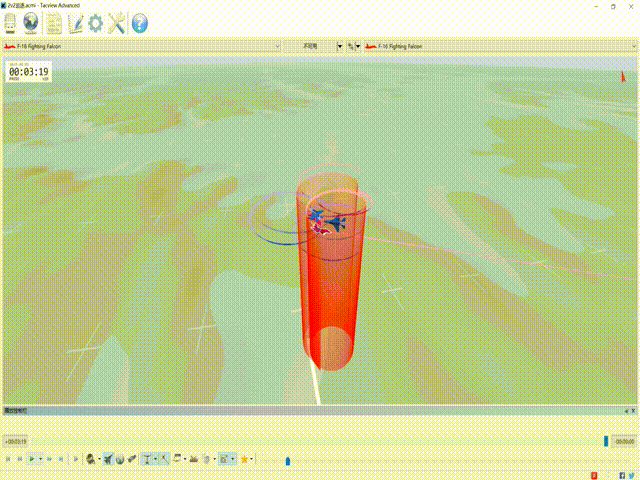
CloseAirCombat is a competitive environment for red and blue aircrafts games, which includes single control setting, 1v1 setting and 2v2 setting. The flight dynamics based on JSBSIM, and missile dynamics based on our implementation of proportional guidance. Official Link: liuqh16/CloseAirCombat
In MARLlib we supports three scenario including extended multi-agent vs Bot games just like tasks such as SMAC. We will test and support more scenarios in the future. Our fork: Theohhhu/CloseAirCombat_baseline
|
Competitive + Cooperative |
|
Cooperative + Mixed |
|
Partial |
|
MultiDiscrete |
|
1D |
|
No |
|
No |
|
No |
|
Dense |
|
Simultaneous |
Installation#
pip install torch pymap3d jsbsim==1.1.6 geographiclib gym==0.20.0 wandb icecream setproctitle
cd Path/To/MARLlib
# we use commit 8c13fd6 on JBSim, version is not restricted but may trigger potential bugs
git submodule add --force https://github.com/JSBSim-Team/jsbsim.git marllib/patch/aircombat/JBSim/data
API usage#
from marllib import marl
# competitive mode
env = marl.make_env(environment_name="aircombat", map_name="MultipleCombat_2v2/NoWeapon/Selfplay")
# cooperative mode
env = marl.make_env(environment_name="aircombat", map_name="MultipleCombat_2v2/NoWeapon/vsBaseline")
Hide and Seek#

OpenAI Hide and Seek is a multi-agent reinforcement learning environment where artificial intelligence agents play a game inspired by hide and seek. Hiders and seekers navigate a virtual 3D environment, with hiders attempting to find clever hiding spots and stay hidden, while seekers aim to locate and tag the hiders within a time limit. With unique abilities and strategies, the agents learn and adapt through reinforcement learning algorithms, making it an engaging and competitive platform to explore advanced techniques in multi-agent AI and showcase the potential of complex behaviors in interactive environments. Official Link: openai/multi-agent-emergence-environments
|
Competitive + Mixed |
|
Competitive + Mixed |
|
Partial |
|
MultiDiscrete |
|
1D |
|
No |
|
No |
|
No |
|
Dense |
|
Simultaneous |
Installation#
To execute the following command, it is necessary to install MuJoCo. The installation process is identical to the one explained for MAMuJoCo in the previous section.
cd marllib/patch/envs/hns/mujoco-worldgen/
pip install -e .
pip install xmltodict
# if encounter enum error, excute uninstall
pip uninstall enum34
API usage#
from marllib import marl
# sub task
env = marl.make_env(environment_name="hns", map_name="BoxLocking")
# full game
env = marl.make_env(environment_name="hns", map_name="hidenseek")