Trust Region Policy Optimization Family#
Trust Region Policy Optimization: A Recap#
Preliminary:
Vanilla Policy Gradient (PG)
In reinforcement learning, finding the appropriate learning rate is essential for policy-gradient based methods. To address this issue, Trust Region Policy Optimization (TRPO) proposes that the updated policy should remain within a trust region. TRPO has four steps to optimize its policy function:
sample a set of trajectories.
estimate the advantages using any advantage estimation method (here we adopt General Advantage Estimation (GAE)).
solve the constrained optimization problem using conjugate gradient and update the policy by it.
fit the value function (critic).
And we repeat these steps to get the global maximum point of the policy function.
Mathematical Form
Critic learning: every iteration gives a better value function.
General Advantage Estimation: how good are current action regarding to the baseline critic value.
: computing the policy gradient using estimated advantage to update the policy function.
Policy learning step 1: estimate policy gradient
Policy learning step 2: Use the conjugate gradient algorithm to compute
Policy learning step 3
Here \({\mathcal D}\) is the collected trajectories. \(R\) is the rewards-to-go. \(\tau\) is the trajectory. \(V_{\phi}\) is the critic function. \(A\) is the advantage. \(\gamma\) is discount value. \(\lambda\) is the weight value of GAE. \(a\) is the action. \(s\) is the observation/state. \(\epsilon\) is a hyperparameter controlling how far away the new policy is allowed to go from the old. \(\pi_{\theta}\) is the policy function. \(H_k\) is the Hessian of the sample average KL-divergence. \(j \in \{0, 1, 2, ... K\}\) is the smallest value which improves the sample loss and satisfies the sample KL-divergence constraint.
A more detailed explanation can be found in - Spinning Up: Trust Region Policy Optimisation
ITRPO: multi-agent version of TRPO#
Quick Facts
Independent trust region policy optimization (ITRPO) is a natural extension of standard trust region policy optimization (TRPO) in multi-agent settings.
Agent architecture of ITRPO consists of two modules:
policyandcritic.ITRPO is applicable for cooperative, collaborative, competitive, and mixed task modes.
Preliminary:
Workflow#
In ITRPO, each agent follows a standard TRPO sampling/training pipeline. Note that buffer and agent models can be shared or separately training across agents. And this applies to all algorithms in TRPO family.
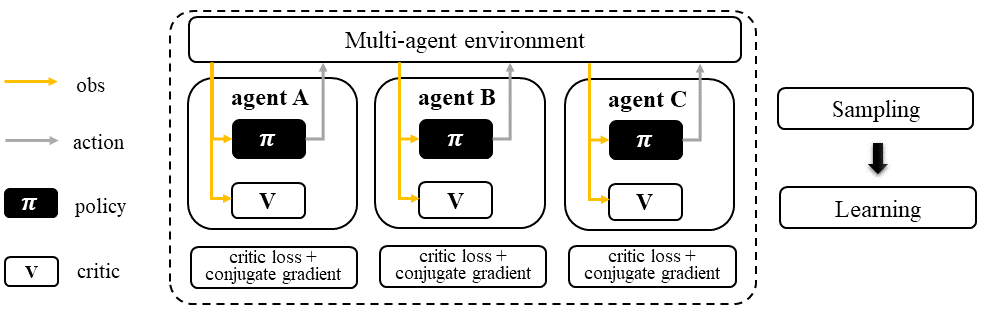
Independent Trust Region Policy Optimization (ITRPO)#
Characteristic#
action space
|
|
task mode
|
|
|
|
taxonomy label
|
|
|
Insights#
ITRPO is a multi-agent version of TRPO, where each agent is a TRPO-based sampler and learner. ITRPO does not require information sharing between agents during training. However, knowledge sharing between agents is optional and can be implemented if desired.
Information Sharing
In the field of multi-agent learning, the term “information sharing” can be vague and unclear, so it’s important to provide clarification. We can categorize information sharing into three types:
real/sampled data: observation, action, etc.
predicted data: Q/critic value, message for communication, etc.
knowledge: experience replay buffer, model parameters, etc.
Traditionally, knowledge-level information sharing has been viewed as a “trick” and not considered a true form of information sharing in multi-agent learning. However, recent research has shown that knowledge sharing is actually crucial for achieving optimal performance. Therefore, we now consider knowledge sharing to be a valid form of information sharing in multi-agent learning.
Mathematical Form#
Standing at the view of a single agent, the mathematical formulation of ITRPO is similiar as Trust Region Policy Optimization: A Recap, except that in MARL, agent usually has no access to the global state typically under partial observable setting. Therefore, we use \(o\) for local observation and :math:`s`for the global state. We then rewrite the mathematical formulation of TRPO as:
Critic learning: every iteration gives a better value function.
General Advantage Estimation: how good are current action regarding to the baseline critic value.
Policy learning step 1: estimate policy gradient
Policy learning step 2 & 3 are the same as Trust Region Policy Optimization: A Recap.
\({\mathcal D}\) is the collected trajectories. \(R\) is the rewards-to-go. \(\tau\) is the trajectory. \(V_{\phi}\) is the critic function. \(A\) is the advantage. \(\gamma\) is discount value. \(\lambda\) is the weight value of GAE. \(u\) is the action. \(o\) is the local observation. \(\epsilon\) is a hyperparameter controlling how far away the new policy is allowed to go from the old. \(\pi_{\theta}\) is the policy function.
Note that in multi-agent settings, all the agent models can be shared, including:
critic function \(V_{\phi}\).
policy function \(\pi_{\theta}\).
Implementation#
We implement TRPO based on PPO training pipeline of RLlib. The detail can be found in:
TRPOTorchPolicyTRPOTrainer
Key hyperparameter location:
marl/algos/hyperparams/common/trpomarl/algos/hyperparams/fintuned/env/trpo
MATRPO: TRPO agent with a centralized critic#
Quick Facts
Multi-agent trust region policy optimization (MATRPO) is one of the extended version of ITRPO: multi-agent version of TRPO.
Agent architecture of MATRPO consists of two models:
policyandcritic.MATRPO is applicable for cooperative, collaborative, competitive, and mixed task modes.
Preliminary:
Workflow#
During the sampling stage of MATRPO, agents share information such as observations and predicted actions with each other. Once each agent collects the necessary information from the others, they can begin the standard TRPO training pipeline. The only difference is that a centralized value function is used to calculate the Generalized Advantage Estimation (GAE) and conduct the TRPO policy learning and critic learning procedure. This allows the agents to take into account the actions and observations of their teammates when updating their policies.
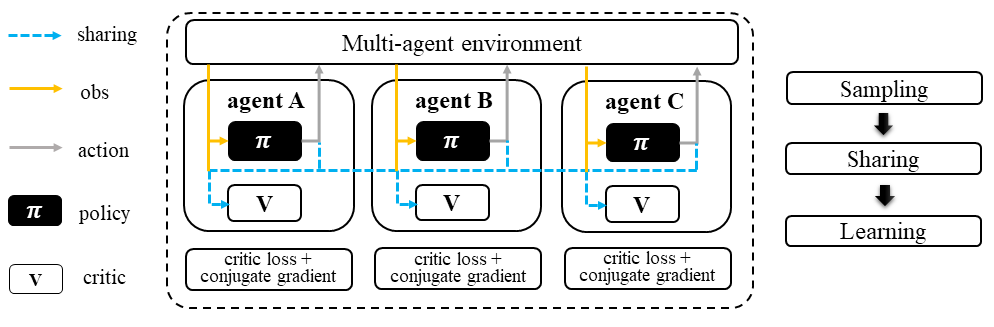
Multi-agent Trust Region Policy Optimization (MATRPO)#
Characteristic#
action space
|
|
task mode
|
|
|
|
taxonomy label
|
|
|
Insights#
MATRPO and MAPPO: PPO agent with a centralized critic are very alike of their features, only the decentralized policy is optimized in the TRPO manner in MATRPO instead of PPO manner.
Mathematical Form#
MATRPO needs information sharing across agents. Critic learning utilizes self-observation and information other agents provide, including observation and actions. Here we bold the symbol (e.g., \(u\) to \(\mathbf{u}\)) to indicate more than one agent information is contained.
Critic learning: every iteration gives a better centralized value function.
General Advantage Estimation: how good are current action regarding to the baseline critic value.
Policy learning step 1: estimate policy gradient
Policy learning step 2 & 3 are the same as Trust Region Policy Optimization: A Recap.
Here \(\mathcal D\) is the collected trajectories that can be shared across agents. \(R\) is the rewards-to-go. \(\tau\) is the trajectory. \(A\) is the advantage. \(\gamma\) is discount value. \(\lambda\) is the weight value of GAE. \(u\) is the current agent action. \(\mathbf{u}^-\) is the action set of all agents, except the current agent. \(s\) is the global state. \(o\) is the local observation \(\epsilon\) is a hyperparameter controlling how far away the new policy is allowed to go from the old. \(V_{\phi}\) is the value function, which can be shared across agents. \(\pi_{\theta}\) is the policy function, which can be shared across agents.
Implementation#
Based on ITRPO, we add centralized modules to implement MATRPO. The details can be found in:
centralized_critic_postprocessingcentre_critic_trpo_loss_fnCC_RNN
Key hyperparameter location:
marl/algos/hyperparams/common/matrpomarl/algos/hyperparams/fintuned/env/matrpo
HATRPO: Sequentially updating critic of MATRPO agents#
Quick Facts
Heterogeneous-Agent Trust Region Policy Optimisation (HATRPO) algorithm is based on MATRPO: TRPO agent with a centralized critic.
Agent architecture of HATRPO consists of three modules:
policy,critic, andsequential updating.In HATRPO, agents have non-shared
policyand sharedcritic.HATRPO is proposed to solve cooperative and collaborative tasks.
Workflow#
HATRPO is a variant of TRPO in which each agent still shares information with others during the sampling stage, but the policies are updated sequentially rather than simultaneously. In the updating sequence, the next agent’s advantage is computed using the current sampling importance and the former advantage, except for the first agent, whose advantage is the original advantage value.
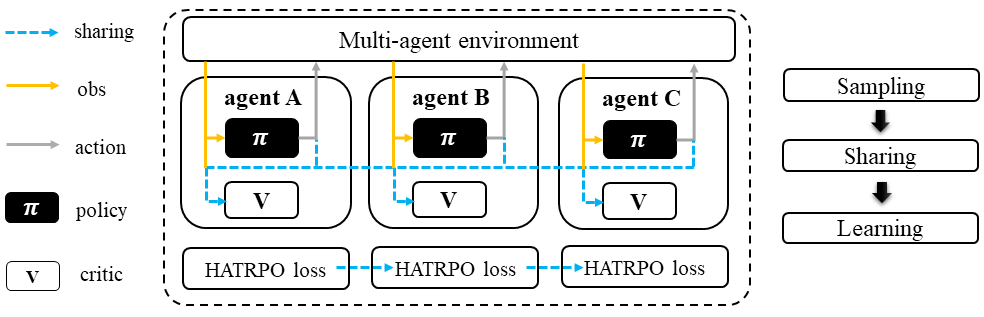
Heterogeneous-Agent Trust Region Policy Optimization (HATRPO)#
Characteristic#
action space
|
|
task mode
|
|
taxonomy label
|
|
|
Insights#
Preliminary
The previous methods either hold the sharing parameters for different agents or lack the essential theoretical property of trust region learning, which is the monotonic improvement guarantee. This could lead to several issues when dealing with MARL problems. Such as:
If the parameters have to be shared, the methods could not apply to the occasions that different agents observe different dimensions.
Sharing parameters could suffer from an exponentially-worse suboptimal outcome.
although ITRPO/MATRPO can be practically applied in a non-parameter sharing way, it still lacks the essential theoretical property of trust region learning, which is the monotonic improvement guarantee.
The HATRPO paper proves that for Heterogeneous-Agent:
Theoretically-justified trust region learning framework in MARL.
HATRPO adopts the sequential update scheme, which saves the cost of maintaining a centralized critic for each agent in CTDE(centralized training with decentralized execution).
Some Interesting Facts
A similar idea of the multi-agent sequential update was also discussed in dynamic programming, where artificial “in-between” states must be considered. On the contrary, HATRPO sequential update scheme is developed based on the paper proposed Lemma 1, which does not require any artificial assumptions and holds for any cooperative games
Bertsekas (2019) requires maintaining a fixed order of updates that is pre-defined for the task, whereas the order in MATRPO is randomised at each iteration, which also offers desirable convergence property
Mathematical Form#
Critic learning: every iteration gives a better value function.
Initial Advantage Estimation: how good are current action regarding to the baseline critic value.
Advantage Estimation for m = 1: how good are current action regarding to the baseline critic value of the first chosen agent.
Advantage Estimation if m > 1: how good are current action regarding to the baseline critic value of the chosen agent except the first one.
Estimate the gradient of the agent’s maximisation objective.
HessianoftheaverageKL-divergence
Use the conjugate gradient algorithm to compute the update direction.
Estimate the maximal step size allowing for meeting the KL-constraint
Update agent 𝑖𝑚’s policy by
Here \({\mathcal D}\) is the collected trajectories. \(R\) is the rewards-to-go. \(\tau\) is the trajectory. \(A\) is the advantage. \(\gamma\) is discount value. \(\lambda\) is the weight value of GAE. \(u\) is the current agent action. \(\mathbf{u}^-\) is the action set of all agents, except the current agent. \(s\) is the global state. \(o\) is the local information. \(\epsilon\) is a hyperparameter controlling how far away the new policy is allowed to go from the old. \(V_{\phi}\) is the value function. \(\pi_{\theta}\) is the policy function. \(B\) is batch size \(T\) is steps per episode \(j \in {0, 1, \dots, L}\) is the smallest such 𝑗 which improves the sample loss by at least \(\kappa \alpha^{j} \hat{\beta}_{k}^{i_{m}} \hat{\boldsymbol{x}}_{k}^{i_{m}} \cdot \hat{\boldsymbol{g}}_{k}^{i_{m}}\), found by the backtracking line search.
Implementation#
Based on MATRPO, we add four components to implement HATRPO. The details can be found in:
hatrpo_loss_fnhatrpo_post_processTrustRegionUpdatorHATRPOUpdator
Key hyperparameter location:
marl/algos/hyperparams/common/hatrpomarl/algos/hyperparams/fintuned/env/hatrpo