Advanced Actor Critic Family#
Advanced Actor-Critic: A Recap#
Preliminary:
Vanilla Policy Gradient (PG)
Monte Carlo Policy Gradients (REINFORCE)
You might be wondering why we need an advanced actor-critic (A2C) algorithm when we already have policy gradient method variants like REINFORCE. Well, the thing is, these methods are not always stable during training due to the large variance in the reward signal used to update the policy. To reduce this variance, we can introduce a baseline. A2C tackles this issue by using a critic value function, which is conditioned on the state, as the baseline. The difference between the Q value and the state value is then calculated as the advantage.
Now we need two functions \(Q\) and \(V\) to estimate \(A\). Luckily we can do some transformations for the above equation. Recall the bellman optimality equation:
\(A\) can be written as:
In this way, only \(V\) is needed to estimate \(A\) Finally we use policy gradient to update the \(V\) function by:
The only thing left is how to update the parameters of the critic function:
Here \(V\) is the critic function. \(\phi\) is the parameters of the critic function. \({\mathcal D}\) is the collected trajectories. \(R\) is the rewards-to-go. \(\tau\) is the trajectory.
IA2C: multi-agent version of A2C#
Quick Facts
Independent advanced actor-critic (IA2C) is a natural extension of standard advanced actor-critic (A2C) in multi-agent settings.
Agent architecture of IA2C consists of two modules:
policyandcritic.IA2C is applicable for cooperative, collaborative, competitive, and mixed task modes.
Preliminary:
Workflow#
The IA2C algorithm employs a standard A2C sampling and training pipeline for each of its agents, making it a reliable baseline for all multi-agent reinforcement learning (MARL) tasks with consistent performance. It’s worth noting that the buffer and agent models can be either shared or separately trained among agents, which is a feature that applies to all algorithms within the A2C family.
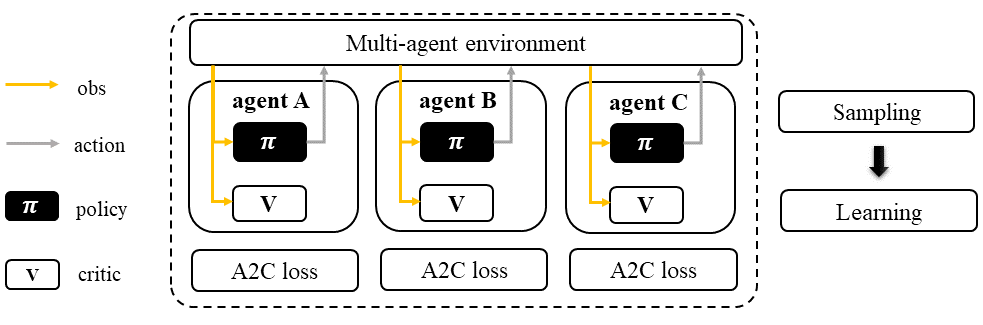
Independent Advanced Actor-Critic (IA2C)#
Characteristic#
action space
|
|
task mode
|
|
|
|
taxonomy label
|
|
|
Insights#
IA2C is a straightforward adaptation of the standard A2C algorithm to multi-agent scenarios, where each agent acts as an A2C-based sampler and learner. Unlike some other multi-agent algorithms, IA2C does not require information sharing among agents to function effectively. However, the option to share knowledge among agents is available in IA2C.
Information Sharing
In the field of multi-agent learning, the term “information sharing” can be vague and unclear, so it’s important to provide clarification. We can categorize information sharing into three types:
real/sampled data: observation, action, etc.
predicted data: Q/critic value, message for communication, etc.
knowledge: experience replay buffer, model parameters, etc.
Traditionally, knowledge-level information sharing has been viewed as a “trick” and not considered a true form of information sharing in multi-agent learning. However, recent research has shown that knowledge sharing is actually crucial for achieving optimal performance. Therefore, we now consider knowledge sharing to be a valid form of information sharing in multi-agent learning.
Mathematical Form#
When considering a single agent’s perspective, the mathematical formulation of IA2C is similar to that of A2C, with the exception that in multi-agent reinforcement learning (MARL), agents often do not have access to the global state, especially under partial observable settings. In this case, we use :math:o to represent the local observation of the agent and :math:s to represent the global state. The mathematical formulation of IA2C can be rewritten as follows to account for this:
Critic learning: every iteration gives a better value function.
Advantage Estimation: how good are current action regarding to the baseline critic value.
Policy learning: computing the policy gradient using estimated advantage to update the policy function.
Note that in multi-agent settings, all the agent models can be shared, including:
value function \(V_{\phi}\).
policy function \(\pi_{\theta}\).
Implementation#
We use vanilla A2C implementation of RLlib in IA2C.
Key hyperparameter location:
marl/algos/hyperparams/common/a2cmarl/algos/hyperparams/fintuned/env/a2c
MAA2C: A2C agent with a centralized critic#
Quick Facts
Multi-agent advanced actor-critic (MAA2C) is one of the extended versions of IA2C: multi-agent version of A2C.
Agent architecture of MAA2C consists of two models:
policyandcritic.MAA2C is applicable for cooperative, collaborative, competitive, and mixed task modes.
Preliminary:
Workflow#
In the sampling stage, agents share information with others. The information includes others’ observations and predicted actions. After collecting the necessary information from other agents, all agents follow the standard A2C training pipeline, except using the centralized critic value function to calculate the GAE and conduct the A2C critic learning procedure.
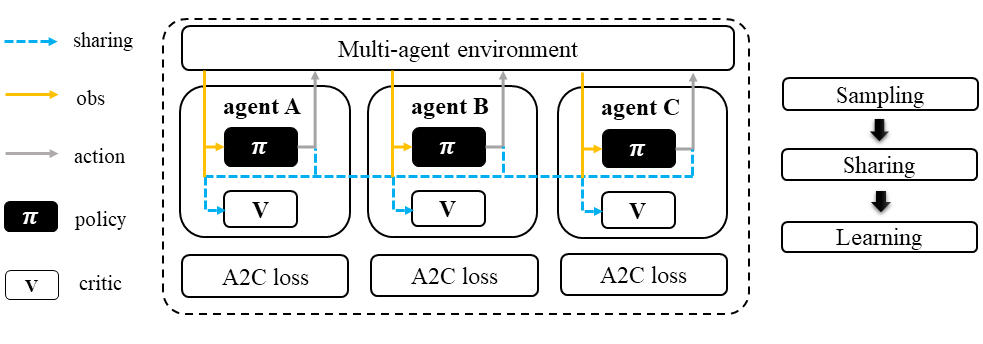
Multi-agent Advanced Actor-Critic (MAA2C)#
Characteristic#
action space
|
|
task mode
|
|
|
|
taxonomy label
|
|
|
Insights#
The use of a centralized critic has been shown to significantly improve the performance of multi-agent proximal policy optimization (MAPPO) in multi-agent reinforcement learning (MARL). This same architecture can also be applied to IA2C with similar success. Additionally, MAA2C can perform well in most scenarios, even without the use of a centralized critic. While there is no official MAA2C paper, we have implemented MAA2C in the same pipeline as MAPPO, using an advanced actor-critic loss function. Our implementation has shown promising results in various MARL tasks.
Mathematical Form#
MAA2C needs information sharing across agents. Critic learning utilizes self-observation and global information, including state and actions. Here we bold the symbol (e.g., \(u\) to \(\mathbf{u}\)) to indicate that more than one agent information is contained.
Critic learning: every iteration gives a better value function.
Advantage Estimation: how good are current action regarding to the baseline critic value.
Policy learning: computing the policy gradient using estimated advantage to update the policy function.
Here \(\mathcal D\) is the collected trajectories that can be shared across agents. \(R\) is the rewards-to-go. \(\tau\) is the trajectory. \(A\) is the advantage. \(\gamma\) is discount value. \(\lambda\) is the weight value of GAE. \(o\) is the current agent local observation. \(u\) is the current agent action. \(\mathbf{u}^-\) is the action set of all agents, except the current agent. \(s\) is the current agent global state. \(V_{\phi}\) is the critic value function, which can be shared across agents. \(\pi_{\theta}\) is the policy function, which can be shared across agents.
Implementation#
Based on IA2C, we add centralized modules to implement MAA2C. The details can be found in:
centralized_critic_postprocessingcentral_critic_a2c_lossCC_RNN
Key hyperparameter location:
marl/algos/hyperparams/common/maa2cmarl/algos/hyperparams/fintuned/env/maa2c
COMA: MAA2C with Counterfactual Multi-Agent Policy Gradients#
Quick Facts
Counterfactual multi-agent policy gradients (COMA) is based on MAA2C.
Agent architecture of COMA consists of two models:
policyandQ.COMA adopts a counterfactual baseline to marginalize a single agent’s action’s contribution.
COMA is applicable for cooperative, collaborative, competitive, and mixed task modes.
Preliminary:
Workflow#
In the sampling stage, agents share information with each other, including their observations and predicted actions. Once the necessary information has been collected, all agents follow the standard A2C training pipeline. However, in order to update the policy, agents use the counterfactual multi-agent (COMA) loss function. Similar to MAA2C, the value function (critic) is centralized. This centralized critic enables agents to effectively learn from the collective experience of all agents, leading to improved performance in MARL tasks.
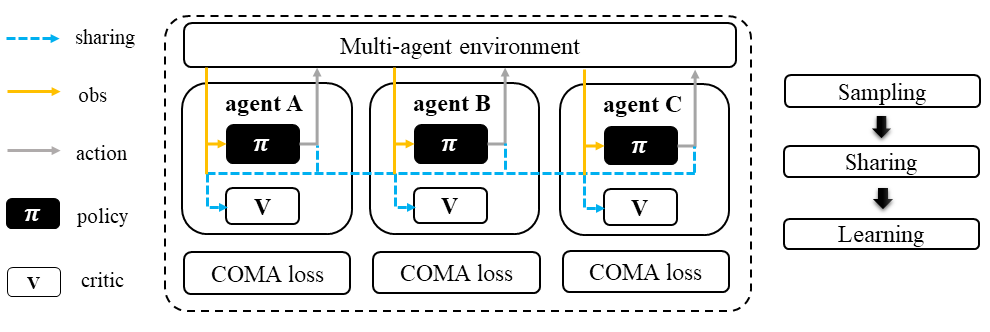
Counterfactual Multi-Agent Policy Gradients (COMA)#
Characteristic#
action space
|
task mode
|
|
|
|
taxonomy label
|
|
|
Insights#
Efficiently learning decentralized policies is an essential demand for modern AI systems. However, assigning credit to an agent becomes a significant challenge when only one global reward exists. COMA provides one solution for this problem:
COMA uses a counterfactual baseline that considers the actions of all agents except for the one whose credit is being assigned, making the computation of the credit assignment more effective.
COMA also utilizes a centralized Q value function, allowing for the efficient computation of the counterfactual baseline in a single forward pass.
By incorporating these techniques, COMA significantly improves average performance compared to other multi-agent actor-critic methods under decentralized execution and partial observability settings.
You Should Know
While COMA is based on stochastic policy gradient methods, it has only been evaluated in the context of discrete action spaces. Extending this method to continuous action spaces can be challenging and may require additional techniques to compute the critic value. This is because continuous action spaces involve a potentially infinite number of actions, making it difficult to compute the critic value in a tractable manner.
While COMA has shown promising results in improving average performance over other multi-agent actor-critic methods under decentralized execution and partial observability settings, it is worth noting that it may not always outperform other MARL methods in all tasks. It is important to carefully consider the specific task and setting when selecting an appropriate MARL method for a particular application.
Mathematical Form#
COMA requires information sharing across agents. In particular, it uses Q learning which utilizes both self-observation and global information, including state and actions of other agents.
One unique feature of COMA is its use of a counterfactual baseline for advantage estimation, which is different from other algorithms in the A2C family. This allows for more accurate credit assignment to individual agents, even when there is only one global reward.
Q learning: every iteration gives a better Q function.
Marginalized Advantage Estimation: how good are current action’s Q value compared to the average Q value of the whole action space.
Policy learning:
Here \({\mathcal D}\) is the collected trajectories. \(R\) is the rewards-to-go. \(\tau\) is the trajectory. \(A\) is the advantage. \(o\) is the current agent local observation. \(u\) is the current agent action. \(\mathbf{u}^-\) is the action set of all agents, except the current agent. \(s\) is the global state. \(Q_{\phi}\) is the Q function. \(\pi_{\theta}\) is the policy function.
Implementation#
Based on IA2C, we add the COMA loss function. The details can be found in:
centralized_critic_postprocessingcentral_critic_coma_lossCC_RNN
Key hyperparameter location:
marl/algos/hyperparams/common/comamarl/algos/hyperparams/fintuned/env/coma
VDA2C: mixing a bunch of A2C agents’ critics#
Quick Facts
Value decomposition advanced actor-critic (VDA2C) is one of the extensions of IA2C: multi-agent version of A2C.
Agent architecture of VDA2C consists of three modules:
policy,critic, andmixer.VDA2C is proposed to solve cooperative and collaborative tasks only.
Preliminary:
Workflow#
During the sampling stage, agents exchange information with other agents, including their observations and predicted critic values. After gathering the required information, all agents follow the usual A2C training pipeline, with the exception of using a mixed critic value to calculate the Generalized Advantage Estimation (GAE) and perform the critic learning procedure for A2C.
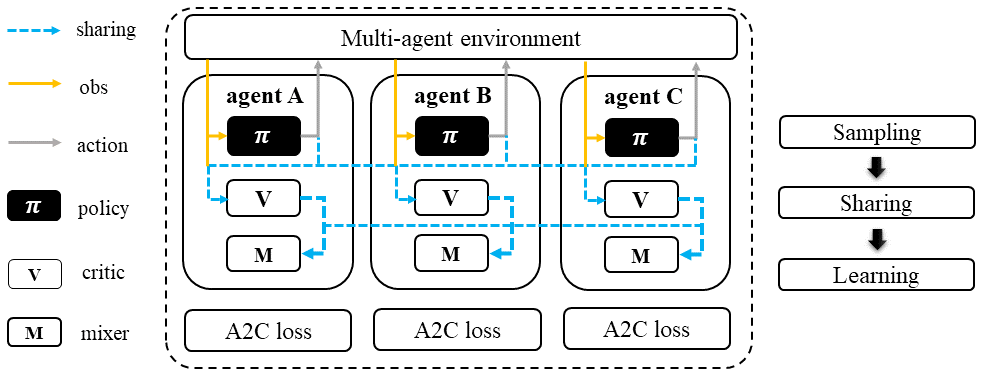
Value Decomposition Advanced Actor-Critic (VDA2C)#
Characteristic#
action space
|
|
task mode
|
|
taxonomy label
|
|
|
Insights#
To put it simply, VDA2C is an algorithm that focuses on assigning credit to different actions in multi-agent settings. It does this by using a value function, called the V function, which is different from the Q function used in other similar algorithms. VDA2C uses on-policy learning and is applicable to both discrete and continuous control problems. However, it may not be as efficient as other joint Q learning algorithms in terms of sampling.
Mathematical Form#
VDA2C needs information sharing across agents. Therefore, the critic mixing utilizes both self-observation and other agents’ observation. Here we bold the symbol (e.g., \(u\) to \(\mathbf{u}\)) to indicate that more than one agent information is contained.
Critic mixing:
Mixed Critic learning: every iteration gives a better value function and a better mixing function.
Advantage Estimation: how good are current joint action set regarding to the baseline critic value.
Policy learning: computing the policy gradient using estimated advantage to update the policy function.
Here \(\mathcal D\) is the collected trajectories that can be shared across agents. \(R\) is the rewards-to-go. \(\tau\) is the trajectory. \(A\) is the advantage. \(\gamma\) is discount value. \(\lambda\) is the weight value of GAE. \(o\) is the current agent local observation. \(u\) is the current agent action. \(\mathbf{u}^-\) is the action set of all agents, except the current agent. \(s\) is the current agent global state. \(V_{\phi}\) is the critic value function, which can be shared across agents. \(\pi_{\theta}\) is the policy function, which can be shared across agents. \(g_{\psi}\) is a mixing network, which must be shared across agents.
Implementation#
Based on IA2C, we add mixing Q modules to implement VDA2C. The details can be found in:
value_mixing_postprocessingvalue_mix_actor_critic_lossVD_RNN
Key hyperparameter location:
marl/algos/hyperparams/common/vda2cmarl/algos/hyperparams/fintuned/env/vda2c